.webp)


Back in the days before Incremental Refresh was available, we were debating Azure Analysis Services vs Power BI, and partitions were a big part of that discussion. We have moved on since then, but I still get many questions about Incremental Refresh, hence writing this blog.
So what is Incremental Refresh?
Incremental Refresh is a way to improve model refresh performance. By creating partitions, it reduces the amount of data that needs to be processed. In short, you do not refresh the entire model, you refresh only what has changed.
Please note, when you look at the MS documentation you will notice it covers incremental refresh and “real-time data”. This blog will be focused more on incremental refresh, but will briefly touch upon DirectQuery partitions as we progress.
What Incremental Refresh is not!
When helping organisations optimise solutions or upskilling in advanced Power BI training, I also regularly hear that incremental refresh is the simplest way to make models faster, less memory hungry, and more performant. Not true! If you ask me, the “simplest” way to do this is by removing everything and anything that is not needed: rows, columns, tables, the whole lot! So, if you are reading this for the purpose of optimising your Power BI Semantic Model, then don’t let features/capabilities like incremental refresh, composite models or aggregation tables be your first optimisation techniques. Start with more of the basics like removing unneeded rows/columns, promoting query folding, etc. If you want a full end-to-end checklist on what to do then download out Free Power BI Performance & Best Practice Checklist.
What are the Benefits of Incremental Refresh?
Here are a few reasons we should be using incremental refresh.
- Faster refresh due to shorter refresh periods, meaning only the difference (delta) needs to be refreshed. No more full refresh all the time.
- Happy users as refresh complete faster and the latest information is available. No more waiting for the morning reports to finish refreshing.
- Solutions are more reliable and fail less, as the amount of data that needs to be refreshed and long running connections to the data source are reduced.
- Less resources consumed, so naturally less memory to be consumed. Also, this can reduce other resources such as CU.
In summary, we wouldn’t want to refresh the entire historical data that hasn’t changed in our enterprise data warehouse, so why should we be doing this in our Power BI semantic models?!
Incremental Refresh Example Case
Let’s say we have a large fashion retailer. They have created a Power BI semantic model that pulls data from their data warehouse as an Import - don’t know what Import and storage modes are, read this: Power BI Storage Modes Demystified.
For this retailer, they are ingesting millions of records and the model size is approximately 4.5GB and growing. It goes down to the day level and SKU (most detailed Product ID) level. All buying and merchandising reports are using this model, plus finance requires it. It hold historical data going back 5 years and in total takes around 1 hour to refresh.
The reports pulling data from this model are displayed daily, hence a daily refresh cadence is required. Now think of it like this, the business has a growing concern of how this solution will scale as it already takes 1 hour, it contains 5 years history and in some occasions the refresh fails. Doesn’t this all sound crazy? Why should we refresh a 4.5GB model that holds the 5 year history every single day. Also, this is transactional data so the historical data does not change.
For this reason, the retailer configured incremental refresh to only update the last 3 months worth of data. This reduced the model refresh from 1 hour to under 10 mins and the likelihood of refresh failure dropped drastically.
Incremental Refresh vs Partitions? I’m Confused!
Incremental refresh works through the policies which are defined directly in Power BI Desktop as you can see below:
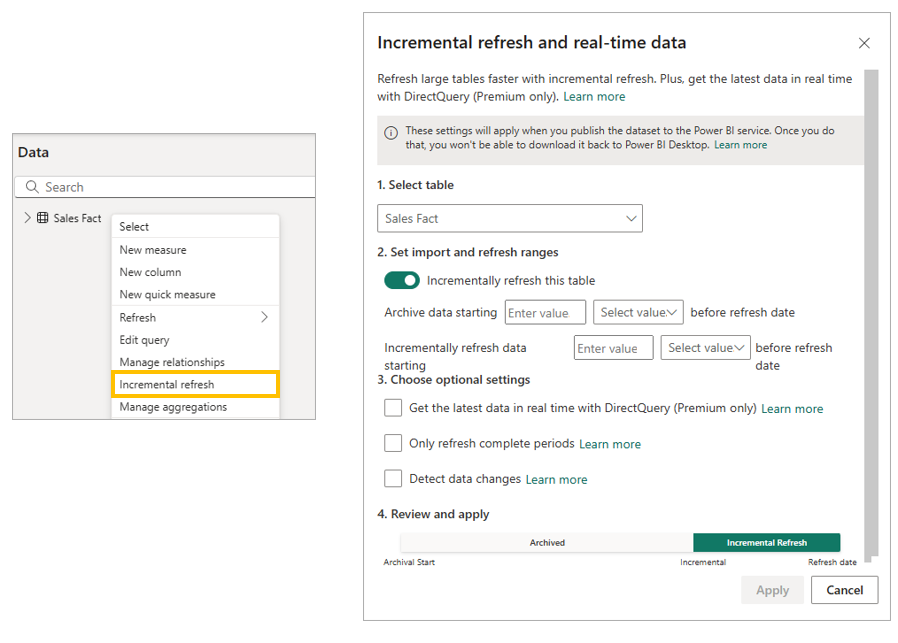
This policy determines what partitions will be created once the model is published to the Power BI Service.
If we don’t configure incremental refresh, each table will be made up of one partition. See below the screenshot - I haven’t configured incremental refresh and using Tabular Editor I can see one partition for my Sales Fact table. All rows exist within this single partition.

So, think of a partition as a slice of the data that has been split by time period. We have the latest partitions that need to be refreshed and the historical partitions where data should be untouched - don’t require a refresh. Please note, for real-time data element which is not discussed in this blog in detail, we would also create DirectQuery partitions.
However, if we do configure incremental refresh then Power BI will create multiple partitions depending on the policy created in Power BI Desktop. We will have partitions that are to be refreshed and historical partitions. Below is a screenshot of the same tables, but this time the Sales Fact has multiple partitions due to configuring incremental refresh.
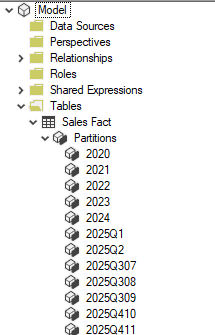
Also it’s very important to note, the physical partitions aren’t created in Power BI Desktop at the point of creating the policy. Even though we configure the incremental refresh policy in Desktop, they are only established when published to the Power BI Service and the first full refresh happens.
What License must I have for Incremental Refresh?
As of now, you can use incremental refresh with Power Pro, Power BI Premium per User (PPU) and a Fabric capacity. In the past, I remember this being a Premium only feature - same with Paginated Reports, but MS done well and brought these over to the per user licensing models. As for the DirectQuery element, this still requires a Fabric (Premium) capacity.
Can I use incremental refresh with any data source?
Incremental Refresh works best with relational, foldable sources such as a SQL database. A simple list of supported sources is not really applicable here as eligibility depends on the data source you need and the setup you have. Instead, we should consider these two items:
Filterable Date/Time Column: The table you enable incremental refresh for should have an applicable column of date data type. Think of things like "Order Date" in the retail context, as this can define the archive and refresh periods required. Also, a date like "Last Modified" could be used to further optimise the incremental refresh policy with the option "Detect data changes", but more on this later.
Query Folding of the Date Filter: The source should support query folding. If you don't know what this is think of it as Power BI sending a message back to the source, asking it to do the transformation work and provide the ready data. So, when we create the RangeStart and RangeEnd parameters (also more on this further below) in Power Query, they should be pushed down to the source. Keep in mind, for query folding to be enabled it depends on the data sources (the connector) and existing transformations steps as some steps can stop query folding even on those sources that support it. For more details on query folding have a look at: Query Folding Overview.
Now, when we go to the incremental refresh policy prompt for configuring it, you may see the warning “Unable to confirm if the M query can be folded. It is not recommended to use incremental refresh with non-foldable queries". This is displayed below:
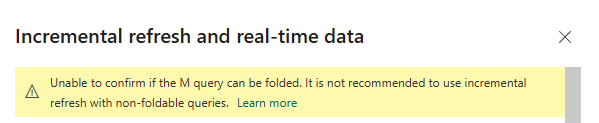
From looking at the MS documentation, for sources that are SQL enabled such as a SQL Server Database, Oracle database and Azure Synapse, this verification is reliable. However, for other sources it might not be reliable and therefore should be checked. But the point is Power BI is warning us and in fact telling us it's not recommended to use incremental refresh with non-foldable queries. The natural question here might be, why? Well, if query folding is not enabled, Power BI would pull all rows first and only then apply the date filter locally. That explodes refresh time, increases resource usage and can trigger timeouts, out-of-memory errors, throttling and capacity spikes. We should understand that the entire purpose of incremental refresh was to increase performance, but without query folding the benefit of incremental refresh is lost.
Also, two side note, if you are using near real time data with DirectQuery partitions you must have query folding enabled for it to work. You could also use incremental refresh with other non relational sources but more configuration/thinking would be required here.
Set Up Incremental Refresh in Power BI
Lets now explore how we can set up incremental refresh, and how some of the elements mentioned above such as the Power Query editor, the parameters (RangeStart/RangeEnd) and the date column, come into play.
Step 1) Create RangeStart and RangeEnd Parameters
We must first create two parameters named RangeStart and RangeEnd. Keep in mind these names are reserved for this purpose. Also, both should be of Date/Time data type - I find many keep them as Date and find issues, so make sure they are Date/Time even if you don't have a time in your date field. Here you will need to add a date for each, and as expected Power BI Desktop will only display the data between these two dates when you load the data into the Power BI model (when you click "Close & Apply" in Power Query. When this is published to the Power BI Service the full data will appear but more on this as we progress.
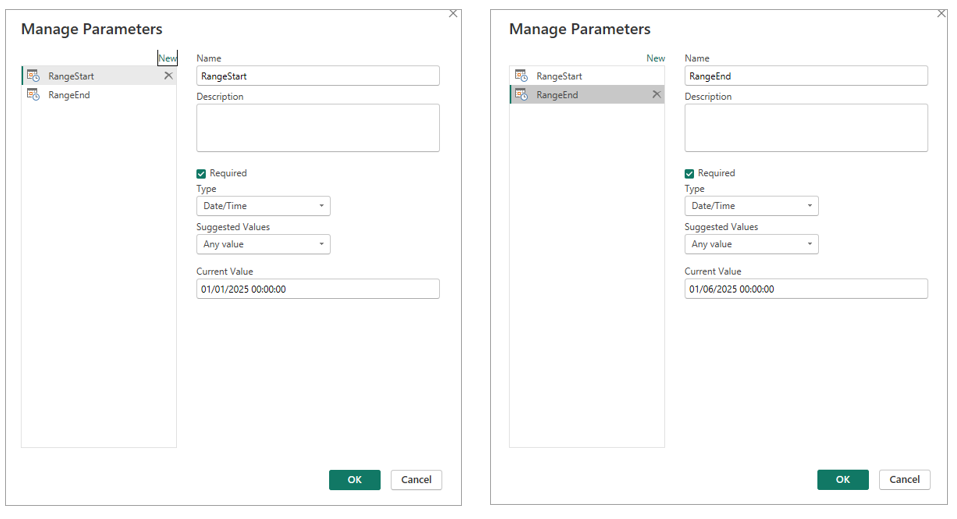
What you enter in these parameters is up to you, just remember that Desktop will only load that slice of data. If you set a very narrow period, you will not have historical rows to test things like This Year vs Last Year DAX measures. Also be aware that if your report and model live in the same PBIX, visuals may look empty at this stage because only the filtered sample is loaded. But again, once you publish and run the first refresh in the Service, the incremental refresh policy overrides these Desktop parameter values and the full historical period is populated.
Step 2) Apply the Date Filter in Power Query
Now that we have the two parameters we need to apply them in Power Query. For this, we must have an applicable date column as we mentioned above in this blog. So, inside our Sales Fact table (sticking to retail context) we have the "OrderDate". So, we need to apply: [OrderDate] >= RangeStart and [OrderDate] < RangeEnd), as the below screenshot illustrates. As mentioned above, we should ensure this filter is being folded back to the source, so keep it early in the query and keep folding intact. One simple way to check folding is to right-click the step in Applied Steps and see if "View Native Query" is available. If it is greyed out, something might be off. That said, this does work always as on some sources I have worked with (Snowflake, Databricks), that option is not shown even when folding is actually happening. In those cases, I always refer to the blog by Chris Webb: Another Way to Check Query Folding.
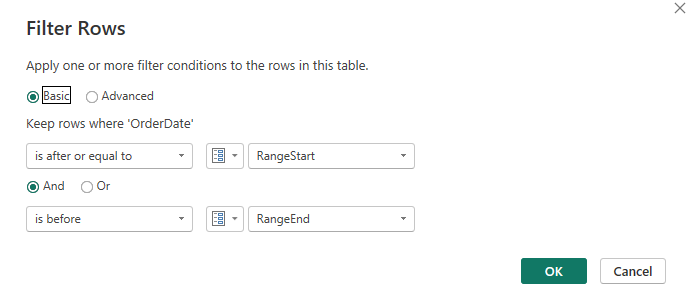
I also want to say, choosing the right date column is a business decision too. In the retail context, a Sales Fact usually lands at the transaction date level, so "OrderDate" is the natural date because it reflects when the sale happened and aligns with reporting. When we move to the incremental refresh policy settings you will see how we also need to consider a few more elements such as how far back is something likely to change, let's say refunds or late adjustments.
Step 3) Define the Policy in Power BI Desktop
We now move along in implementing incremental refresh as we define an incremental refresh policy. Continuing from the retail example, the model holds five years of historical data, is about 4.5 GB, goes to the date and SKU level, takes roughly 1 hour to refresh and needs a daily refresh so the business sees yesterday’s sales performance. Based on that, in the Incremental refresh policy settings we will set "Archive data starting 5 Years before refresh date" so all history remains in the model. Then we will set "Incrementally refresh data starting to 3 Months before refresh date" so only the most recent three months are rebuilt on each refresh while older periods stay frozen. This keeps full history available but limits processing to the hot window, turning a 1 hour long full refresh into a short incremental one.
Also, if you are thinking why we chose 3 months it's because it matches the business reality, changes (e.g., refunds, late adjustments) rarely occur beyond the retailer’s 90 day refund policy. In other words, the refresh window is a business decision, set it to cover how far back data is likely to change.
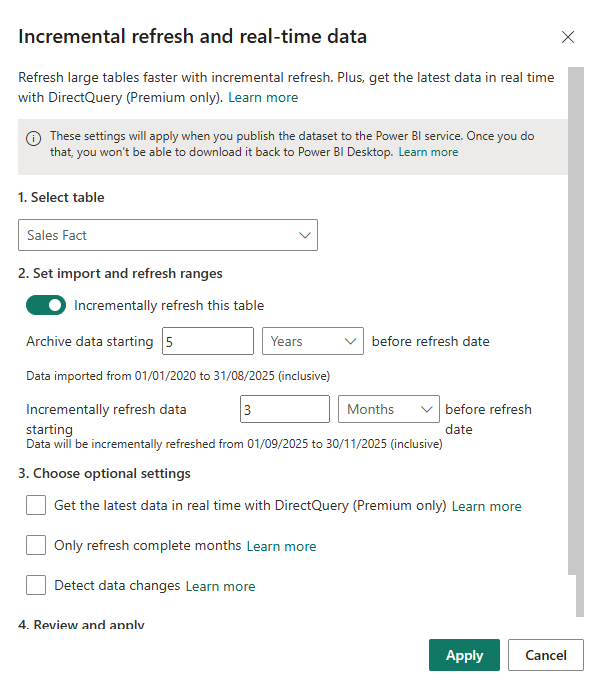
Note, we will skip the optional settings you can see above such as "Get the latest data...", "Only refresh complete periods", "Detect data changes", etc. and review them later.
One thing I want to call out, I also like the little narrative under the inputs. So, once you set the archive and refresh periods, the dialog spells out the exact date ranges such as “Data imported from 01/01/2020 to 31/08/2025 (inclusive)” and “Data will be incrementally refreshed from 01/09/2025 to 31/11/2025 (inclusive)”. It is a quick sanity check that helps you verify you are pulling the right history and rebuilding only the intended period. Also, a lot of people at this point are confused as they think this is an issue as it does not align to the values entered in the RangeStart/RangeEnd parameters. Not at all, when we publish to the Power BI Service, what you see above in the policy is what will take affect, it overwrites the parameter default values. One last point, as you can see below, the incremental refresh policy also provides a helpful visual to see the configuration.

Step 4) Publish and Run the First Refresh
We have now come to the last step, of saving the pbix file and publishing the solution to the Power BI Service. Keep in mind what is happening, the solution and its model as of now will only contain data that is between the RangeStart and RangeEnd parameter. The incremental refresh policy would not have taken affect at the point of creating it and clicking "Apply". So, after you publish if the model has large volumes of data you may need to enable the Large model format feature on before you run a heavy refresh process. The initial run will refresh all the partitions as it loads the full archive periods (5 Years) and rebuilds the current refresh periods, so it can take a while. However, every refresh after that is much quicker because only the incremental partitions (3 Months) are processed based on the policy.
Two quick notes, once an incremental refresh model has been published and refreshed, you generally cannot download it back as a PBIX from the Service, so keep your source file safe. Also, schedule that first seed outside business hours if the dataset is large.
Optional settings - When (and When Not) to Use Them
Above we went through the process of understanding incremental refresh and reviewed the incremental refresh setup. In step 3, I purposely missed some elements just to keep the process easier to follow. However, below I offer a brief explanation of each one and what incremental refresh allows.
Get the latest data in real time with DirectQuery: Adds a DirectQuery partition on top of the Import partitions so users can see rows that arrived after the current refresh period. It requires PPU or Fabric (premium workspace is required), and query folding must be enabled for this to work. In short, this will essentially create a hybrid table and as mentioned throughout this blog i am not focusing here, but likely to write an entire blog on this feature.
Only refresh complete months/periods): This tells Power BI to ignore the current, incomplete period and refresh only finished months (or days, if you partition is daily). It is ideal when upstream loads trickle in during the day and you want to avoid half-filled partitions.
Detect data changes: This is the one I get most questions about and my upfront recommendation is do use this if you can. This will further optimise the refresh, as instead of refreshing the refresh partitions (due to be refreshed), it will only refresh those partitions that have actually changed. Please note, you cannot use the same date column you used to configure the incremental refresh. Think of a column like "LastModifiedDate", this is the applicable date column to use here. How does it work? Well, it takes the max day from the "LastModifiedDate" column and on the next refresh it checks to see if there is a newer max date, if yes that partition is refreshed, if not its not. So, this shortens refreshes and reduces load.
Avoid Overwriting Your History When Republishing
When you republish the Power BI data model from Desktop to the Power BI Service, it will overwrite the Service model (which holds full historical data) with partial data - whatever is specified by your Desktop parameters.
Many people get caught out here, so please keep this in mind. Now, if you want to add something to the model such as a measure, do not worry, you do not need to republish and overwrite the entire history. I've seen many do this. Use the ALM Toolkit. I have been using this approach for many years, so if you are aware of a better approach please let me know. The ALM Toolkit enables what is known (or what I still call) metadata only deployments. In fact, looking at the site it states “Easy Deployment – Retain partitions to avoid reprocessing partitioned tables”, which is exactly what we need. It is out of scope for this blog to go into detail, but in summary: using ALM Toolkit, connect to the semantic model in the Service (which has the full history) as the Target and in the ALM settings ensure the processing option does not have Full Refresh selected, then from a local Desktop version which is the source, update the target in the Service. Keep in mind, if we want to add new rows to the historical data, so the partitions we created that are not to be refreshed we need to do a full refresh. Also, from what I remember for any core structural changes it does get tricker but depending on your requirements it may be possible - reach out if you have questions. I should also say you can achieve the same metadata-only deployment using Power BI Deployment Pipelines, which copy metadata (not data) between stages and preserve partitions, then you refresh in the target stage.
Important Notes
Once you publish a model with incremental refresh and run the first refresh in the Service, the download of PBIX option is not available. This is why it's so important to have some form of version control, whether Git, SharePoint folders or anything else. Also, be aware that refresh time limits still apply. Incremental refresh does not bypass refresh timeouts. On Pro the limit is 2 hours per refresh and with on PPU and Fabric it is 5 hours. Lastly, we also have APIs to automate this, use the Power BI REST API for triggering/scheduling refreshes and XMLA to script partition management and incremental policies.
Summary
You should now know what incremental refresh is and feel more comfortable configuring it. In the blog, I tried my best to also give input from my own personal experience using this feature over the years. Remember, this is not a magic speed button - don't use this as the first step to optimising your model. First try the options like removing unused columns/rows, reducing high cardinality columns, promoting query folding and more, which can all be found here in my Free Power BI Performance & Best Practice Checklist. Incremental refresh creates partitions for refreshing only what changes and keeps historical data as is.


%20(8).png)
.avif)
